참고 자료
https://en.wikipedia.org/wiki/Mel_scale
https://m.blog.naver.com/sooftware/221661644808
1. Introduction
나는 음성과 인공지능을 결합하는 작업에 관심을 가지고 있다.
그래서 그와 관련된 연구/프로젝트를 많이 찾아서 하고 있는 중이다.
요즘에는 크게 1) 머릿속 내부 발화(Inner Speech)의 Voice Reconstruction 연구, 2) 통화 데이터 기반 실시간 인공지능 거짓말(보이스피싱) 탐지기 개발 이렇게 두 가지의 프로젝트를 하는데, 이 두 프로젝트 모두 공통적으로 음성 데이터에서 어떻게 유의미한 feature를 뽑아낼 것인지에 대한 고민이 필요하다.
이러한 좋은 feature를 뽑아낼 수 있는 대표적인 방법이 Mel-Spectrogram과 MFCC(Mel-Frequency Cepstral Coefficiency)인데, 오늘은 그 중 첫 번째인 멜 스펙트로그램(Mel-Spectrogram)에 대하여 정리하고자 한다.
2. 사람은 어떻게 소리를 듣는가
사람은 소리를 달팽이관을 통해 인식한다.
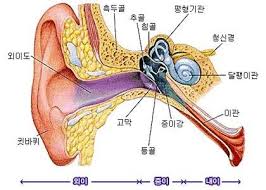
그림을 보듯 달팽이관은 동그랗게 말려있다. 그러나 이를 길게 펴서 보면 달팽이관의 각 부분이 서로 다른 주파수를 인지하고 있다.
사람은 이 달팽이관이 감지하는 주파수를 기반으로 소리를 인식하고, 이러한 이유로 인공지능에서도 주파수를 feature로 사용한다.
하지만, 달팽이관은 특수한 성질이 있다.
저주파수 대역에서는 주파수의 변화(즉, 소리의 변화)를 잘 감지하는데,
고주파수 대역에서는 주파수의 변화를 잘 감지하지 못한다는 것이다.
(실제로 사람은 2000Hz~3000Hz 구간의 소리에 비해 12000Hz~13000Hz 구간의 소리를 잘 인식하지 못한다.)
구조상으로도 달팽이관에서 저주파 대역을 감지하는 부분은 굵지만 고주파 대역을 감지하는 부분으로 갈수록 얇아진다고 한다.
3. 멜 스펙트로그램(Mel-Spectrogram)은 왜 필요한가 : Mel-Scale
그렇다면, feature vector로 주파수를 그대로 쓰기보다 달팽이관의 특성에 맞춰서 특징을 뽑는 게 더욱 효과적인 피쳐 추출 방법일 것이다.
인공지능은 사람을 위한 기술이고, 사람이 듣는 대로 소리를 인식하는 것이 사람의 문제를 해결하기에 더 적합할 테니까 말이다.
이렇게 사람 달팽이관 특성을 고려한 값을 Mel-scale이라고 한다.
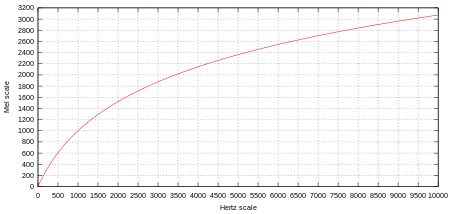
이렇게 Mel-scale을 고려하여 소리를 스펙트로그램화한 것을 '멜 스펙트로그램'이라고 한다.
스펙트로그램(Spectrogram)이 뭐지?
스펙트로그램은 소리나 파동을 시각화하여 파악하기 위한 도구로, 파형(waveform)과 스펙트럼(spectrum)의 특징이 조합되어 있다.
파형(waveform)은 신호의 모양과 형태이다. sine파나 cosine파를 떠올려 보면 위아래로 곡선을 그리며 움직이는 모양을 상상할 수 있는데, 그 구불구불 움직이는 선의 모양이 바로 파형이다. 파형의 x축은 시간(Time), y축은 진폭(Amplitude)이다.
스펙트럼(spectrum)은 다양한 성분음들의 주파수(Frequency)와 진폭(Amplitude)을 표시한 것이다. x축은 주파수, y축은 진폭이다. 위키백과는 '어떤 복합적인 신호를 가진 것을 1~2가지 신호에 따라 분해해서 표시하는 기술'이라고 설명하고 있다.
그래서, 이들을 조합한 스펙트로그램은 x축에 시간(Time), y축에 주파수(Frequency), z축에 진폭(Amplitude)를 나타내는 방식으로 구성되어 있다.



응용 사례를 보면,
음성 인식 시스템에서는 멜 스펙트로그램을 통해 추출된 특징이 음성과 비음성 구간을 구분하기도 하고,
환경 소리 감지에도 중요하게 쓰이며,
음악 장르 분류나 감정 분석에서도 멜 스펙트로그램이 중요한 특징으로 활용된다고 한다.
예를 들어, 나같은 경우는 음성(통화) 데이터를 기반으로 프로젝트를 수행하다 보니 통화 데이터가 수집될 때 주변 컴퓨터 등 전자기기의 영향으로 고주파가 같이 녹음될 수 있다. 이런 노이즈들의 영향력을 줄이는 데에도 멜 스펙트로그램이 기여할 수 있다.
추가로,
일반적인 task에 F0 / pitch 등 handcraft feature를 사용하기에는 사실 피처의 개수가 너무 적고, 내가 뽑기로 한 그 feature가 내 task에 기여를 할 지 학습 전에 제대로 알 수 없다. 멜 스펙트로그램은 한 음성에서 (생성 시 설정하는 옵션인 n_mels에 따라) 일반적으로 80개이상의 feature가 한 번에 뽑히는 개념이라, feature engineering을 수행하지 않는 딥러닝 접근법에서 훨씬 효율적이다.
4. 멜 스펙트로그램(Mel-Spectrogram)의 원리
https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53
Understanding the Mel Spectrogram
(and Other Topics in Signal Processing)
medium.com
이 글이 아주 설명을 잘 해둬서, 이 포스트 참고 바랍니다.
5. 구현
librosa 라이브러리를 주로 이용한다.
위 링크에서 가져온 코드인데, 순서대로 정리하면 이렇다.
1. 라이브러리 import 및 데이터 로드
import librosa
import librosa.display
import matplotlib.pyplot as plt
y, sr = librosa.load('./example_data/blues.00000.wav')
2. 만약 신호가 어떻게 생겼는지 보고 싶다면,
plt.title('Signal')
plt.xlabel('Time (samples)')
plt.ylabel('Amplitude')
plt.plot(y)아래와 같은 그림이 plot된다.

3. Spectrogram
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)librosa.display.specshow(spec, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')과정은 다음과 같다.
- y에 단시간 푸리에 변환(STFT)를 수행하고, 이 값에 복소수 절대값을 취한다.
이 때 hop_length는 연속하는 프레임 사이의 샘플 수이다.(값이 클 수록 시간 해상도는 줄고 주파수 해상도가 늘어난다.)
- librosa.amplitude_to_db에서는 스펙트럼의 크기를 데시벨(dB) 단위로 변환한다.
왜 데시벨 단위로 바꾸냐? 묻는다면 데시벨은 로그 스케일을 사용하는데, 이를 통해 스펙트럼의 세부적인 차이를 더 잘 시각화하기 위함이다.
- librosa.display.specshow() 함수는 스펙트로그램을 그래프로 표시한다
sr는 샘플링율(sampling_rate) 값이고,
x_axis='time'는 x축을 시간으로 설정하며, y_axis='log'는 y축을 로그 스케일로 설정하여 주파수를 표시한다.
이를 통해 낮은 주파수 영역에서 더 많은 세부 정보를 볼 수 있게 한다.
여기까지 했다면 아래처럼 스펙트로그램이 plot된다. (아직 멜 스펙트로그램은 아니다.)

4. Mel-Spectrogram
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time')
plt.title('Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')- librosa.feature.melspectrogram을 통해 y에 대해 멜 스펙트로그램을 계산한다.
sr는 오디오 샘플의 샘플링 레이트를 의미하고,
n_fft은 FFT를 계산할 때 사용되는 윈도우 크기를 지정한다. 이 크기가 크면 주파수 해상도는 높아지고 시간 해상도는 낮아진다.
hop_length는 인접한 프레임 사이의 샘플 수를 지정한다.
- librosa.power_to_db는 멜 스펙트로그램의 파워 값을 데시벨 단위로 변환하여 동적 범위를 압축하고 로그 스케일로 표현한다. (단순 멜 스펙트로그램 말고 로그 멜 스펙트로그램 구하기 위해 사용된다.)
이제 진짜 멜 스펙트로그램이 완성됐다.

현재는 librosa 라이브러리 기준으로만 설명하였는데, 오디오 도메인에서 주로 쓰이는 라이브러리인 torchaudio, kaldi 각각 멜 스펙트로그램을 생성하더라도 라이브러리 간 장단점이나 특성이 다르다. 이 부분은 추후 보완하도록 하겠다.
6. 정리하며
공부를 하며 가장 헷갈렸던 부분이,
'그럼 Mel-Spectrogram 자체가 feature인가?' 였는데,
Mel-Spectrogram은 feature를 잘 뽑아낼 수 있도록 소리 신호의 특성을 변경해주는 과정일 뿐이다.
변형된 값에서, 즉 Mel-Spectrogram에서 유의미한 feature를 뽑는 과정은 별개로 이루어져야 한다.
맞다. Mel-spectrogram / Log Mel-spectrogram 그냥 통으로 넣는다.
Mel-Spectrogram과 같이 다루는 개념이 MFCC인데,
다음 글에서는 이 MFCC에 대하여 다뤄 보고자 한다.
'[Audio & Speech Fundamentals]' 카테고리의 다른 글
| [202002]A Framework for the Robust Evaluation of Sound Event Detection (6) | 2025.01.08 |
|---|---|
| Audio & Speech 기본 개념 (10) | 2025.01.03 |
| 자주 쓰이는 Acoustic feature와 추출 방법 (6) | 2024.05.07 |
| MFCC(Mel Frequency Cepstral Coefficient) 간단 정리 (9) | 2024.05.07 |