(Reference) Hyeong-Seok, Choi., Juheon, Lee., Wan-Soo, Kim., Jie, Hwan, Lee., Hoon, Heo., Kyogu, Lee. (2021). Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations.. arXiv: Sound
이 논문에서는 neural analysis and synthesis(NANSY)라는, 사람 음성 신호의 voice, pitch, speed을 조절할 수 있는 프레임워크를 소개한다. NANSY는 음성에 대한 세부 사항(라벨 등) 없이, 원래 소리의 일부를 혼합하여 고품질 제어로 재구성(reconstruction)하는 방법론이다.
1. Introduction
1) 기존 Voice Conversion application 연구의 문제점
기존의 Voice Conversion application은 크게 1) Text-based approach, 2) Information bottleneck approach의 두 가지 방식으로 이루어졌으나, 두 방법 모두 한계가 존재했다.
먼저, 텍스트 기반 접근(Text-based approach)은 텍스트 모달리티가 화자 식별 정보와 본질적으로 분리되어 있다는 점을 이용한다.
그러나 이 방식의 한계점은,
자동 음성 인식(ASR) 네트워크를 사용하여 Phonetic Posteriorgram (PPG)을 추출하거나 텍스트 스크립트를 직접 사용했으나,
ASR 네트워크의 언어 의존성 때문에 다국어 환경 또는 저자원 언어에 모델을 확장하는 데 한계가 있었다는 점이다.
(Automatic Speech Recognition)ASR?
- 음성 신호를 입력으로 받아들여 텍스트로 변환하는 기술이다. ASR은 음성 인식 엔진을 사용하여 음성 신호를 분석하고 인간의 음성을 텍스트로 해석하는 과정을 수행한다. 이러한 기술은 음성 명령 및 제어 시스템, 음성 인터페이스, 음성 검색, 음성 대화 시스템 등 다양한 응용 분야에서 사용된다. (출처 : https://wikidocs.net/120051)
(Phonetic Posteriorgram)PPG?
- 음성 처리 분야에서 사용되는 시각화 도구이다. 주로 음성 인식 시스템이나 음성 분류 알고리즘의 결과를 시각화하는 데 사용되며, 특히 음소별 분류 확률을 보여주는 데 초점이 맞춰져 있다. 여기서 주로 다룰 내용은 아니기 때문에 자세한 설명은 생략한다.
다음으로 정보 병목(information bottleneck) 기반 접근 방식은 정보 흐름을 제한하여 분석 기능을 분리하는 방법이다.
그러나 이 방식 역시 한계가 존재했는데,
1. 분석 기능을 분리하기 위해 정보 병목 구조를 사용하지만 낮은 재구성 품질로 인해 제약 발생
2. 재구성 품질과 특징 분리 간의 트레이드오프 존재
등이 대표적이었다.
2) NANSY 프레임워크
이러한 문제를 해결하기 위해 NANSY는 기존의 텍스트 기반 접근 방식을 피하고 두 가지 분석 기능인 wav2vec과 Yingram을 사용하여 음성 신호를 분석한다.
- wav2vec 2.0은 텍스트 정보를 사용하지 않고도 53개 언어에 대해 self-supervised 방식으로 학습한 기능으로, 언어 간 장벽을 뛰어넘는 language-agnostic한 언어 정보를 제공한다.
- 동시에 새로운 피치 특징인 Yingram을 제안하여 피치 정보를 효과적으로 표현하고 하모닉 및 서브하모닉 정보를 포함한다.
Yingram : 기존 피치 추정 방법인 f0 대신 Yin 알고리즘을 변형한 새로운 피치 기능이고, 이는 피치 정보를 효과적으로 표현하며 하모닉 정보도 포함한다.
이를 통해 음성 변환 작업을 수행할 때 고품질 재구성과 제어 가능성을 모두 확보할 수 있다.
이 NANSY는 몇 가지 특징을 가지고 있는데,
첫 번째로 정보 교란 전략(information perturbation)이다.
NANSY 프레임워크의 핵심은 정보 교란 전략이다. 기존의 정보 병목 접근 방식이 아닌 정보 교란(information perturbation)을 통해 입력 음성 신호의 정보를 교란함으로써 재구성 네트워크가 핵심 속성을 선택적으로 추출하도록 훈련한다. 예를 들어, wav2vec 기능에서는 언어(linguistic) 정보만 추출하도록 하고, Yingram에서는 피치(pitch) 정보만을 추출하도록 교란 전략을 활용합니다. 이러한 방식으로 NANSY는 고품질 재구성과 분리된 특징을 동시에 달성하며, 완전히 자가 지도 방식으로 학습할 수 있다.
두 번째로 테스트 시 자기 적응(test-time self-adaptation, TSA)이다.
음성 신호의 분석 및 재구성 기능이 탁월함에도 불구하고, 미지의 언어에서는 올바른 발음을 생성하는 데 어려움이 있을 수 있다. 이를 해결하기 위해 TSA 기술을 제안했고, TSA는 입력 특징만을 수정하여 재구성 품질을 개선하며, 이를 통해 저자원 언어에서도 빠른 적응이 가능하다.
3) NANSY의 주요 응용 분야
- 제로샷 음성 변환 (Zero-Shot Voice Conversion):
- 화자 정보가 없는 상황에서도 음성을 다른 화자의 음성으로 변환 가능
- 피치 변환 (Pitch Shift):
- 음성 신호의 피치를 자유롭게 변경할 수 있음
- 시간 스케일 변환 (Time-Scale Modification):
- 음성 신호의 속도를 조절할 수 있음
정리하자면,
- 저자는 완전 자가 지도 학습 가능한 NANSY 프레임워크를 제안하였고, 여기에
- 정보 교란 전략과 새로운 분석 기능인 Yingram을 도입했으며,
- 테스트 시 자기 적응(test-time self-adaptation, TSA) 기술을 통해 미지의 언어에도 적응이 가능하도록 하였다.
2. NANSY의 본격적 소개

NANSY 프레임워크의 전체 구조이다. 입력 음성 신호는 먼저 다양한 함수에 의해 perturb되어 wav2vec, Yingram 등이 특정 feature만 추출하도록 유도된다. wav2vec 인코더와 speaker embedding network를 통해 분석 기능을 추출하고, 이를 바탕으로 멜 스펙트로그램을 재구성한다.
1) 분석 기능 (Analysis Features)
NANSY는 음성 신호를 다음의 네 가지 분석 기능으로 분해한다.
1. Linguistic (언어 정보)
음성 신호의 언어 정보를 추출하기 위해 XLSR-53: wav2vec 2.0 모델을 사용한다.
- 이 모델은 53개 언어로 사전 학습된 자가 지도(self-supervised) 모델로, 총 24개의 트랜스포머(transformer) 레이어를 포함하고 있다.
- 각 레이어에서 추출한 특징은 다양한 속성들을 나타내는데, 12번째 레이어는 발음 정보와 가장 관련성이 높다.
- 따라서 NANSY 프레임워크에서는 이 12번째 레이어의 출력을 언어 특징으로 사용한다.
2. Speaker (화자 정보)
화자 정보는 speaker embedding network를 통해 추출된다.
- wav2vec 2.0의 1층 레이어는 speaker cluster를 잘 형성하는 특징을 보여주므로, 이 레이어의 출력을 speaker embedding network의 입력으로 사용한다.
- 화자 임베딩 네트워크는 1D-CNN과 attentive statistics pooling을 결합하여 설계되었으며, 화자 임베딩은 L2 정규화를 거쳐 사용된다.
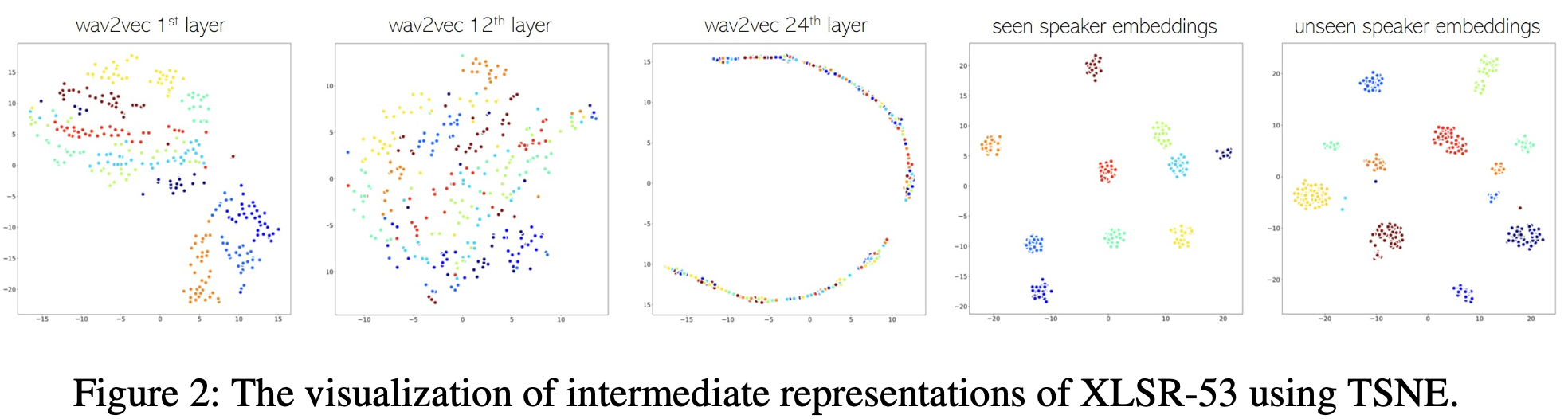
3. Pitch (피치 정보)
앞서 언급한 것처럼, 저자는 피치 정보를 추출하기 위해 새로운 기능인 Yingram을 제안하였다.
- 기존의 피치 기능인 f0는 서브하모닉이나 vocal fry 등의 문제로 정확한 피치 정보를 제공하지 못하는 경우가 있었다.
- Yingram은 Yin 알고리즘을 변형한 것으로, 음성 신호의 하모닉 및 서브하모닉 정보까지 포함한다.
- Yingram의 계산 방법:
- Yin 알고리즘의 누적 평균 정규화 차이 함수 d'를 계산하고, 이를 midi-scale로 변환하여 피치 특징을 생성한다.
- 최종 Yingram은 주파수 범위가 10.77 Hz에서 1000.40 Hz까지 포함되며, 각 미디 노트(midi note) 당 20개의 빈(bin)을 갖는다.
- Yingram의 변환 범위를 조절함으로써 피치 변환이 가능하다.
4. Energy (에너지 정보)
로그 멜 스펙트로그램에서 평균값을 계산하여 에너지 정보를 추출한다.
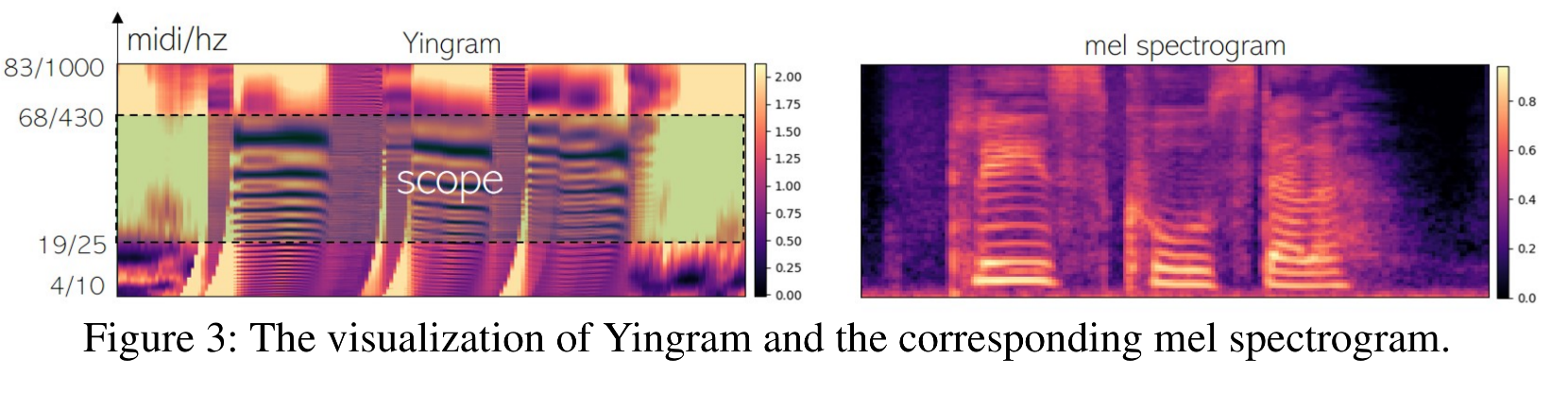
2) 정보 교란(information perturbation)
NANSY 프레임워크의 핵심은 정보 교란(information perturbation) 전략이다.
입력 음성 신호의 정보 일부를 의도적으로 교란하여 각 분석 기능이 특정 속성만을 추출하도록 훈련한다.
- f 함수:
포먼트(formant), 피치(pitch), 주파수 응답(frequency response)을 모두 perturb한다. - g 함수:
포먼트와 주파수 응답만을 perturb하고 pitch는 유지한다.
이러한 perturb을 통해 wav2vec와 Yingram이 원하는 정보만 추출할 수 있도록 네트워크를 훈련한다.

3) 생성 네트워크 (Synthesis Network)
GS와 GF 개요
NANSY는 음성 신호 생성 시 두 개의 네트워크 GS(Source Generator)와 GF(Filter Generator)를 사용한다.
- GS (Source Generator): Yingram과 화자, 에너지 정보를 입력받아 피치 하모닉(pitch harmonics)을 생성한다.
- GF (Filter Generator): wav2vec와 화자, 에너지 정보를 입력받아 스펙트럴 필터(spectral filter)를 생성한다.
생성 방법
최종 멜 스펙트로그램 M̂은 두 생성기의 출력을 합산하여 얻는다.여기서,
- M̂: 생성된 멜 스펙트로그램
- S: 화자 임베딩
- E: 에너지 정보
이고,
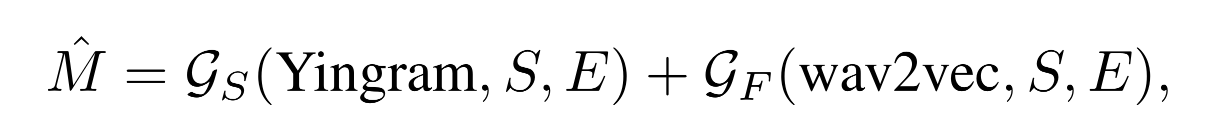
으로 나타낼 수 있다.
네트워크 구조
GS와 GF는 모두 동일한 1D-CNN 구조를 갖추고 있으며 GLU(Gated Linear Units)를 활용한다.
* GLU : https://medium.com/deeplearningmadeeasy/glu-gated-linear-unit-21e71cd52081
최종적으로 생성된 멜 스펙트로그램 M̂은 HiFi-GAN 보코더를 통해 파형으로 변환된다.
* HiFi-GAN : https://github.com/jik876/hifi-gan
3. Training
1) Information Perturbation
1. 정보 교란의 필요성
NANSY의 초기 실험 결과에 따르면, wav2vec 기능만으로도 음성 신호의 멜 스펙트로그램을 쉽게 재구성할 수 있었다.
이는 wav2vec 기능에 피치 및 화자 정보까지 포함되어 있다는 것을 의미한다.
따라서 GF가 언어 정보만 추출하고, GS가 피치 정보만 추출하도록 네트워크를 훈련할 필요가 있다.
2. 교란(perturbation) 함수 f와 g
이를 위해 음성 신호에 대해 두 가지 함수 f와 g를 사용하여 정보를 교란한다.
- f 함수:
- 포먼트(formant), 피치(pitch), 주파수 응답(frequency response)을 모두 교란하여 wav2vec가 언어 정보만을 추출하도록 한다.
- f(x) = fs(pr(peq(x)))
- fs: 포먼트(formant) 변조
- pr: 피치(pitch) 랜덤화
- peq: Parametric equalizer
- g 함수:
- 포먼트와 주파수 응답만을 교란하고 피치 정보를 유지하여 Yingram이 피치 정보만을 추출하도록 한다.
- g(x) = fs(peq(x))
3. 교란의 결과
- 이러한 교란 함수의 사용을 통해 GF는 언어 정보만 추출하고 GS는 피치 정보만 추출하도록 훈련할 수 있다.
- 또한, 화자 정보는 화자 임베딩 네트워크를 통해서만 제어할 수 있다.
2) Training Loss
헉 너무 어렵다...! 수식은 나중에 한번 더 읽고 써야지
3) Test-time Self-Adaptation (TSA)
NANSY는 미지의 언어에 대한 적응을 위해 TSA 기술을 사용한다. TSA는 모델 파라미터를 수정하지 않고 입력 특징만을 수정하여 빠르게 적응할 수 있다.
TSA 훈련 과정
다음과 같은 과정으로 TSA를 수행한다.
- Test-time에 L1 손실을 계산하여 생성된 멜 스펙트로그램 M̂과 실제 멜 스펙트로그램 M 간의 차이를 평가한다.
- 이 손실의 backpropagation signal을 이용하여 파라미터화된 wav2vec의 feature를 업데이트한다. (loss gradient는 filter generator을 통해서만 역전파 되었다.)
- 이 과정을 반복하여 wav2vec 특징을 점차 최적화한다.
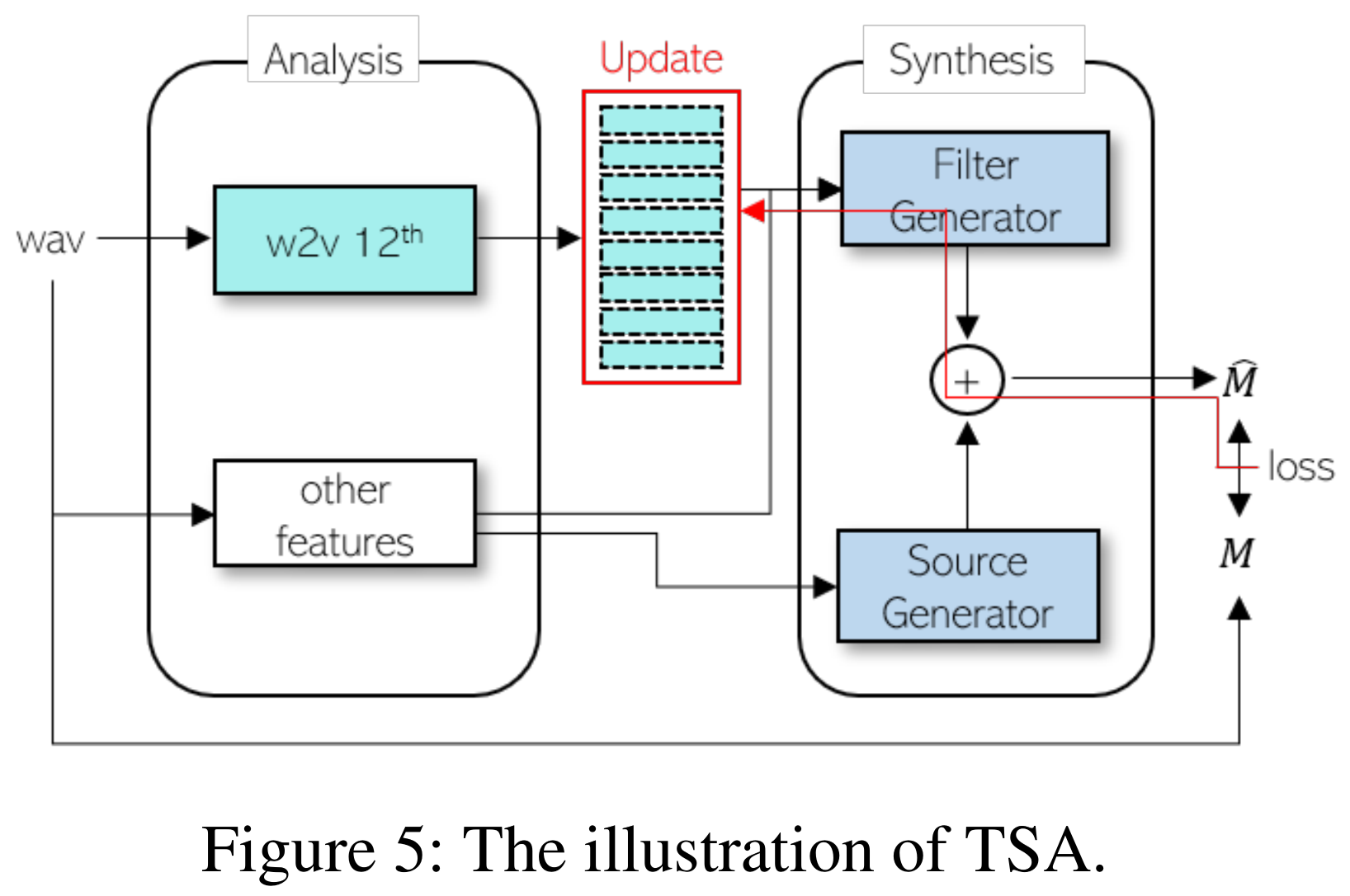
4. Experiments
NANSY 프레임워크의 성능을 평가하기 위해 다양한 실험을 수행하였으며, 각 실험 결과를 바탕으로 프레임워크의 재구성 품질과 적용 가능성을 확인할 수 있다.
1. 실험 설정 (Implementation Details)
- 데이터셋
- 영어 데이터셋:
- VCTK: 여러 화자의 영어 음성 샘플로 구성된 데이터셋 (훈련에 90% 사용)
- LibriTTS (train-clean-360 subset): 대규모 영어 음성 데이터셋 (훈련에 사용)
- 다국어 데이터셋:
- CSS10: 10개 언어에 대한 단일 화자 음성 데이터셋
- 훈련 설정
- 샘플링 레이트: 22,050 Hz
- 멜 스펙트로그램:
- 밴드 수: 80
- FFT 크기: 1024
- 윈도 크기: 1024
- 홉 크기: 256
- 훈련 길이: 각 샘플을 약 1.47초로 무작위로 자름 (총 128 프레임의 멜 스펙트로그램)
- 학습률: 10^(-4)
- 최적화기: Adam (β1 = 0.5, β2 = 0.9)
- 훈련 에폭: 50 에폭
- 하드웨어: NVIDIA RTX 3090 GPU로 훈련
2. 재구성 실험 (Reconstruction)
NANSY의 재구성 품질을 평가하기 위해 다음과 같은 지표를 사용했다.
- CER (Character Error Rate): 문자 오류율
- MOS (Mean Opinion Score): 1~5점 척도로 평가한 음성 품질
- DMOS (Degradation Mean Opinion Score): 1~5점 척도로 평가한 품질 열화 정도
- Yingram vs. f0
기존의 f0 피치 추정과 새로운 Yingram 피치 특징을 비교한 결과, Yingram이 f0보다 68.3%의 선호도를 보이며 더 우수한 재구성 품질을 나타낸다.
- 영어 재구성 실험 결과 (Table 1)
- 데이터셋: VCTK (테스트용 10% 데이터), LibriTTS (test-clean subset)
- 결과:
- CER: 5.6%
- MOS: 4.18
- DMOS: 1.93
- 다국어 재구성 실험 결과 (Table 2)
- 데이터셋: CSS10 (10% 테스트 데이터)
- 결과:
- CER: 7.3%
- MOS: 4.14
- DMOS: 1.74

- TSA
다양한 언어에 대한 적응 성능을 평가하기 위해 NANSY를 세 가지 설정으로 훈련 및 테스트함:
1. ENG: 영어 데이터셋만 사용
2. ENG-TSA: 영어 데이터셋만 사용 + TSA 적용
3. MUL: 다국어 데이터셋 사용
- 결과 (Figure 6):
- TSA 적용 시 (ENG-TSA), 미지의 언어에서도 CER이 ENG 설정보다 낮게 나타나거나 MUL과 비슷한 성능을 보임

3. 음성 변환 (Voice Conversion)
NANSY의 제로샷 음성 변환 성능을 평가하기 위해 세 가지 변환 설정을 테스트했다.
1. Seen-to-Seen (M2M): 훈련된 화자 간 변환
2. Unseen-to-Seen (A2M): 미훈련된 화자에서 훈련된 화자 간 변환
3. Unseen-to-Unseen (A2A): 미훈련된 화자 간 변환
각 설정에서 네 가지 성별 간 조합 (m2m, m2f, f2m, f2f)을 고려하여 총 360개의 변환 쌍을 생성했다.
- 평가 지표
- CER
- MOS
- SSIM (Speaker Similarity, %): 이진 판단 및 불확실성 옵션을 통한 화자 유사도
- 알고리즘 비교 (Table 3)
- Baseline: VQVC+, AdaIN, AUTOVC
- 결과
- NANSY가 모든 설정에서 선행 연구에 비해 CER, MOS, SSIM 측면에서 뛰어난 성능을 보였다.
- 특히 M2M 설정에서 CER이 7.5%에 불과하며, SSIM은 91.4%를 기록했다.

- 다국어 음성 변환 (Table 4)
- 데이터셋: CSS10
- 결과:
- CER: 18.8%
- MOS: 3.68
- SSIM: 69.5%
- 미지의 언어 변환 (Table 5)
NANSY 프레임워크를 통해 미지의 언어 간 음성 변환이 가능함을 확인했다.
- 데이터셋: CSS10
- 설정:
1. Unseen-to-Seen (Seen Speaker)
2. Unseen-to-Unseen (Unseen Speaker)
- 결과:
- Seen Speaker에서의 SSIM은 90.0%, Unseen Speaker에서는 61.0%로 나타남

4. 피치 변환 및 시간 스케일 변환 (Pitch Shift and Time-Scale Modification)
NANSY 프레임워크의 피치 변환 및 시간 스케일 변환 기능을 확인하기 위해 다음과 같은 실험을 수행함.
- 피치 변환 실험 (Table 6)
- 범위: ±6세미톤 (총 5단계)
- 비교 대상: PSOLA, WORLD vocoder
- 결과: NANSY는 모든 세미톤 범위에서 비교 대상보다 더 높은 MOS 점수를 기록함
- 시간 스케일 변환 실험 (Table 7)
- 범위: 1/2배 ~ 2배 (총 5단계)
- 비교 대상: PSOLA, WORLD vocoder
- 결과: NANSY는 모든 시간 스케일에서 비교 대상과 유사하거나 더 높은 MOS 점수를 기록함

5. Conclusion
NANSY 프레임워크는 고품질 음성 분석 및 재구성, 음성 변환 작업을 위해 설계된 자가 지도 학습 기반의 혁신적인 시스템이다.
기존의 텍스트 또는 정보 병목 기반 접근 방식이 가진 한계를 극복하고자 NANSY는 정보 교란 전략(information perturbation strategy)을 통해 음성 신호를 언어, 화자, 피치, 에너지 정보로 분리한다. 이를 통해 기존의 f0 대신 새로운 피치 특징인 Yingram을 사용하고, wav2vec 기능을 활용해 고품질의 언어 특징을 추출함으로써 완전한 제어 가능성과 재구성 품질을 달성했다.
NANSY는 다양한 음성 변환 작업에서 기존 알고리즘보다 뛰어난 성능을 보였다.
- 제로샷 음성 변환(Zero-Shot Voice Conversion)에서 NANSY는 다양한 언어, 화자 간의 음성 변환을 성공적으로 수행하였고,
- 특히 미지의 언어에서도 TSA 기술을 통해 유연하게 적응할 수 있었다.
- 또한 피치 변환(Pitch Shift) 및 시간 스케일 변환(Time-Scale Modification)에서도 높은 품질의 변환 성능을 나타냈다.
실험 결과를 통해 NANSY 프레임워크의 효과적이고 다양한 응용 가능성을 확인할 수 있었다. 향후 연구에서는 음성 신호의 언어 정보까지 제어할 수 있도록 텍스트 정보를 통합하는 하이브리드 접근 방식을 탐구하고자 한다. 이러한 접근 방식을 통해 음성 변환 작업에서 더 풍부하고 다양한 변환을 가능하게 하며, 보다 높은 품질의 음성 합성 기술을 개발할 수 있을 것으로 기대한다.