출처 : Attention is All you Need (neurips.cc)
2016년 Attention Mechanism(1409.0473 (arxiv.org))의 등장은 RNN 계통의 모델들이 갖는 장기 의존성 문제를 해결하는 데에 있어 초석이 되었다. 그리고 2017년에는 Backpropagation을 사용하지 않고 Attention Mechansim만을 활용하여 시퀀스 데이터를 처리할 수 있는, 당시 최고의 성능을 가진 모델 Transformer가 등장하였고, 이는 AI 업계를 크게 뒤흔들어 놓았다(현재는 Mamba와 같은 더욱 성능이 좋은 모델에 대한 최신 논문도 나오고 있다). 우리가 많이 사용하고 있는 'GPT' 또한 그 의미 자체가 General Pre-trained Transformer이니, 얼마나 Transformer의 파급력이 컸는지 알 수 있을 것이다.
오늘은 다양한 도메인에서 높은 성능으로 광범위하게 쓰이고 있는 Transformer와, 이의 바탕이 되는 Attention Mechanism에 대해 간단히 알아보려 한다.
Introduction: RNN의 한계와 Attention Mechanism
RNN은 무엇이 문제였을까?
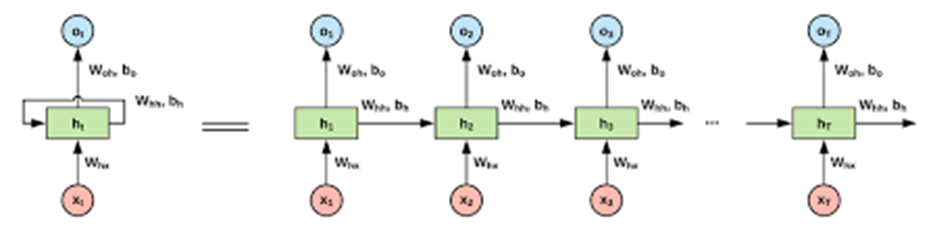
Backpropagation을 활용한 RNN의 도입은 시간 정보를 예측에 활용할 수 있게 되면서, 시간적 의존성을 갖는 데이터(시계열데이터)들에 대한 더욱 우수한 예측이 가능해졌다.
그러나 RNN, 정확히는 Backpropagation은 한가지 치명적인 한계점을 가지고 있었고, 그게 바로 장기 의존성 문제(long-term dependency problem)이다. 장기 의존성 문제는 역전파 특성에 의해 시퀀스 길이가 긴 데이터가 들어오면 들어올 수록 순환하는 레이어가 많아져 Gradient vanishing, 즉 기울기가 소실되어 학습이 제대로 이루어지지 않는 문제이다. 이는 특히 번역기를 비롯한 언어 모델에서 부각되었고, 조금만 문장이 길어져도 급격하게 RNN의 번역 성능이 떨어지곤 했었다.
Attention Mechanism은 순차적으로 데이터를 순환하는 방법 대신, 전체 데이터를 한 번에 병렬 처리하는 방식으로 이러한 문제를 해결할 수 있도록 해주었다.

기존처럼 fixed-length context vector를 사용하는 것이 아닌, 입력 문장의 각 단어에 가중치를 부여하여 디코더가 중요한 부분에 집중할 수 있게 되었고, 덕분에 이를 활용하여 길고 복잡한 문장들에 대한 번역 품질을 향상시킬 수 있게 되었다.
Transformer는 이러한 Attention Mechanism의 한 종류인 Dot-product Attention, Multihead Attention, Self Attention, Cross Attention 등을 활용한다.
Transformer 개요
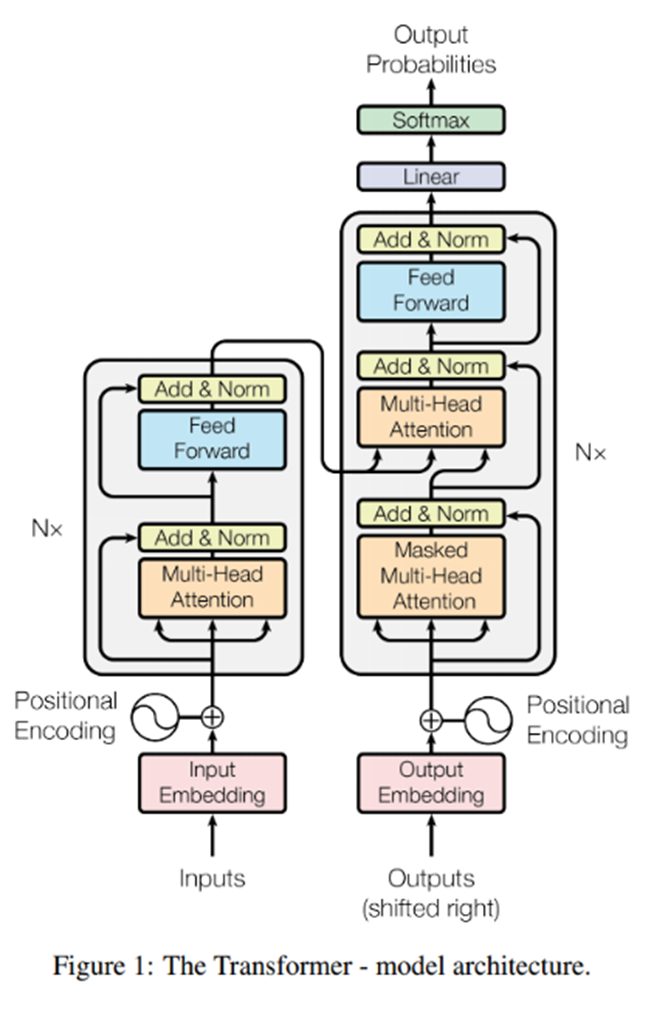
보이는 것처럼 트랜스포머는 복잡한 구조를 가지고 있다. 지금부터 하나하나 가볍게 뜯어보도록 하겠다.
Positional Encoding
순차적으로 정보를 입력받지 않는다고 해서 정보들의 순서가 중요하지 않은 것은 아니다. 그럼 어떻게 정보를 처리해야 할까?
이 논문에서는 'Positional Encoding'이라는 기법을 통해 이러한 문제를 해결했다. 이는 시퀀스 내에서 토큰의 상대적/절대적인 위치 정보를 주입하는 것이다.

그럼 각 토큰 별로 position이 만들어지게 되고, 이를 그림으로 나타내면 다음과 같다.

이러한 Positional Encoding은 포지션의 순서(ex. 2번째 -> 5번째)와 그 위치가 선형 함수 관계를 갖는다.
Attention: Self Attention
Self Attention과 Multihead Attention을 소개한다.
일반 Attention은 한 시퀀스와 다른 시퀀스와의 관계를 이용한다.
- 예를 들어, 'I am a student'와 그의 번역 문장 'je suis etduiant'와의 관계를 비교하는 것이다.
반면 Self Attention은 시퀀스 안에서 다른 요소와의 관계를 고려하는 메커니즘이다.
- 예를 들어, 'I am a student' 안에서 I와 am / a / student 등 다른 단어와의 관계, am과 I / a / student 등 다른 단어와의 관계를 비교한다.
그리고 이러한 Self Attention은 Multihead Attention을 통해 구현된다. (이 내용은 잠시 후 다룸)
그럼 여기서 의문점이 들 것이다. '그래서 Self Attention이 왜 좋은가?' 아래에 정리해 두었다.
Encoder
자, 이제 본격적으로 Encoder에 대해 알아본다.

Encoder의 구조이다.
Positional Encoding을 거치고 난 데이터는 encoder 내의 'Multi-head Self-Attention'이라는 sublayer를 지나게 된다.
이러한 Multihead (self)Attention은 'scaled dot-product attention'을 병렬로 수행하는 어텐션 메커니즘이다.
어라? 아까 Self Attention이 multihead attention으로 구현된다고 하지 않았나? 헷갈릴 것이다. 정리하자면,
Multihead Attention : Scaled dot-product attention의 병렬 수행
Self Attention : Multihead Attention을 통해 '실현됨'
의 관계이다.
그럼 Scaled dot-product attention은 뭘까?
먼저 Encoder에서 연산에 사용되는 Query, Key, Value에 대해 알아보자.
Decoder