Author: Nam Kyun Kim and Hong Kook Kim | IEEE Access
https://ieeexplore.ieee.org/document/9312148
Polyphonic Sound Event Detection Based on Residual Convolutional Recurrent Neural Network With Semi-Supervised Loss Function
Polyphonic sound event detection (SED) is an emerging area with many applications for smart disaster safety, security, life logging, etc. This paper proposes a two-stage polyphonic SED model when strongly labeled data are limited but weakly labeled and unl
ieeexplore.ieee.org
요약
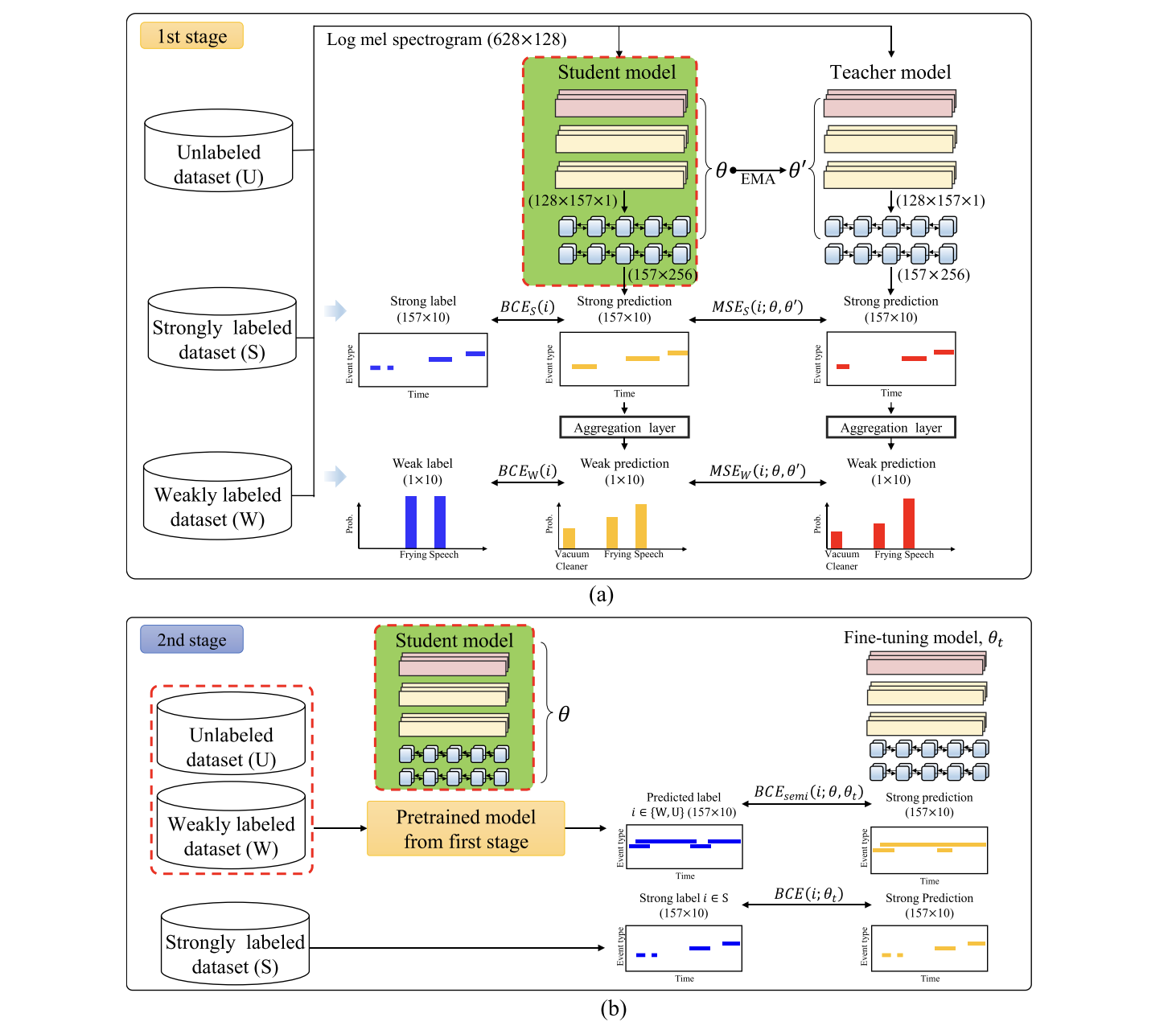
이 논문은 기존 모델들의 한계점을 보완한 two-stage polyphonic 구조 기반 SED 모델을 설명하고 있다.
- First stage에서는 CBAM(Convolutional Block Attention Module) 기반 attention을 활용하는 RCRNN(Residual CRNN) 기반 mean teacher model,
- Second stage에서는 Semi-supervised loss function을 적용하여 first stage에서 제안했던 모델을 기반으로 student model을 파인튜닝 한다.
본 논문에서 제안된 CBAM+RCRNN 구조 모델은 DCASE challenge 2019 task4, 2020 task4 두 챌린지에 적용되었고, F1-score와 Polyphonic Sound Detection Score(PSDS) 두 평가 지표 사용 전제 하에 최고 성능을 보여주었다. 또 semi-supervised loss function을 적용한 two-stage SED model은 DCASE 2019, 2020의 top-ranked model보다 6.1%, 4.6% 높은 F1-score를 기록하였다.
관련 개념 보충
[mean teacher model]
Semi-Supervised Learning에서 쓰이는 기법으로, 이 논문의 데이터셋은 strongly labeled dataset 뿐만 아니라 weakly labeled dataset, unlabeled dataset 등을 함께 포함하기 때문에 이 두 데이터셋을 활용하여 pseudo label*을 만들고 strong labeled dataset처럼 활용하여 전반적인 strong prediction 학습 성능을 올리기 위해 사용된다.
*pseudo label: SSL을 통해 예측된 임시 라벨. 예를 들어 SSL model이 unlabeled data에 대해 라벨 예측을 했다면, 이를 실제 라벨이라고 가정하고 labeled data들과 함께 지도학습에 활용한다. 여기서 SSL이 만들어낸 label을 pseudo label이라고 부른다.
간단하게만 정리하면,
1) 먼저 Student model과 Teacher model를 초기화한 후
2) Student model이 labeled data를 학습하고,
3) 이때 Student model의 EMA(Exponentional Moving Average) 값으로 Teacher model의 가중치를 업데이트한다.
4) labeled data의 학습이 끝나면 teacher model은 EMA에 의해 업데이트된 가중치 값을 기반으로 unlabeled dataset에 대하여 pseudo label을 예측하고, student model은 pseudo labeled data + labeled data에서 주어진 지도학습 예측을 수행한다.
5) 이 과정에서 teacher model은 다시 student model의 EMA를 기반으로 업데이트되고, student model은 teacher model과의 MSE를 줄여나가는 방식으로 업데이트한다. (이걸 왜 하나 조금 이해가 안 갈 수 있는데, 결국 teacher model도 라벨을 예측하고 student model도 라벨을 예측하는데, teacher model이 student model의 EMA 기반으로 학습되었기 때문에 더욱 안정적이라서 student가 teacher를 따라가는 방식을 채택했다고 이해했음)
논문: https://arxiv.org/pdf/1703.01780
레퍼런스: https://velog.io/@tjdcjffff/Mean-teachers-are-better-role-models-Weight-averaged-consistency-targets-improve-semi-supervised-deep-learning-results.2017
[Knowledge Distillation]
Mean teacher model과 비슷한 구조를 가지지만 훈련 방식이나 목적에서 조금 다르다. 기본적으로 동일하게 teacher-student 구조를 가지는데, Knowledge Distillation에서 teacher는 이미 학습이 완료되어 업데이트되지 않고, 더 고품질의 예측을 하지만 computationally expensive한 모델이다. Student는 이 teacher를 모방하도록 학습하는데, 그렇기에 teacher만큼의 예측 성능이 나오진 않지만 계산 비용이 조금 더 낮다.
[Multiple Instance Learning (MIL)]
weakly labeled dataset에서 Bag-level* 정보를 활용해 Instance-level 예측을 가능하게 한다. (특히 SED와 같은 타임스탬프 없는 오디오 태스크에서 중요한 역할)
*Bag-lavel: 단일 예측이 아니라 여러 이벤트가 동시에 발생한 데이터를 줌. Bag-level prediction은 이 Bag-level 정보를 보고 원하는 이벤트가 이 데이터에서 발생했는지 안 발생했는지에 대해서 학습하고, 잘 학습되면 Bag-level 데이터에서 바로 원하는 데이터가 발생했다/안했다를 판단하도록 한다.
레퍼런스: https://velog.io/@hcu55/Multiple-Instance-Learning
[Polyphonic Sound Detection Score(PSDS)]
다중 SED에서 사용되는 평가 지표인데, 단순 이벤트 기반 F1-score나 Error Rate(ER)보다 더 현실적인 평가 지표라고 한다. 자세한 내용을 적기에는 조금 길어져서, 링크에 달아 둔 논문을 참고하도록.
논문: https://arxiv.org/pdf/1910.08440
아키텍처
이어서 계속